Processing TAQ Data Math, CS, Data
For a project I’m working on, I need to deal with historical daily TAQ (Trade and Quote) data for a selection of stocks. Each day’s TAQ file consists of all of the stock transactions that occurred during that trading day. The data were downloaded from the Wharton Research Data Services website, using the Yale Center for Analytical Sciences subscription.
To demonstrate, here are the first few rows of a TAQ file:
SYMBOL,DATE,TIME,PRICE,SIZE,CORR,COND,EX
A,20100104,9:30:02,31.32,98,0,Q,T
A,20100104,9:30:50,31.39,100,0,F,T
A,20100104,9:30:50,31.4,300,0,F,T
A,20100104,9:30:50,31.41,100,0,Q,P
“SYMBOL” refers to the stock’s ticker symbol. “DATE” is a string comprising the year, month, and day of the transaction; it is the same in every row of a given TAQ file. “TIME” is the hour, minute, and second of the transaction, in Eastern Standard Time. “PRICE” is the amount of money exchanged per share of stock in the transaction. “SIZE” is the number of shares traded in the transaction. The other columns are unimportant for my analysis.
Splitting up Big Files
Each raw TAQ data file is too big to open all at once using, for example, read.csv. Attempting to open one on the remote machine I’m using (with 8 GB of RAM) results in memory swapping, slowing the processing to a practical standstill.
Instead, I processed the TAQ files by reading in one line at a time, which uses a negligible amount of memory. I wrote a Python script TAQprocess.py which is shown below. The code is object-oriented, which slows it down somewhat, but in this case, making the code easier to read and manage seemed worth the added computation time.
import sys
import os
import string
def toSeconds(time):
timev = time.split(":")
return(3600*int(timev[0]) + 60*int(timev[1]) + int(timev[2]))
class Line:
def __init__(self, ifile):
self.ifile = ifile
skip = self.ifile.readline()
skip = self.next()
def next(self):
linev = self.ifile.readline().split(",", 5)
if len(linev) == 1:
return False
self.symbol = linev[0]
self.time = toSeconds(linev[2])
self.price = float(linev[3])
self.size = int(linev[4])
return True
class Stock:
def __init__(self, symbol):
self.symbol = symbol
self.ofile = open("Processed/%s/%s.csv" % (sys.argv[1], symbol), "w")
self.write("time,price\n")
def next(self, symbol):
self.close()
self.__init__(symbol)
def write(self, text):
self.ofile.write(text)
def close(self):
self.ofile.close()
class Second:
def __init__(self, line):
self.time = line.time
self.spent = line.price*line.size
self.volume = line.size
def add(self, line):
self.spent += line.price*line.size
self.volume += line.size
def next(self, stock, line):
self.write(stock)
self.__init__(line)
def write(self, stock):
stock.write("%s,%s\n" % (self.time, round(self.spent/self.volume, 2)))
print "Processing %s." % sys.argv[1]
os.makedirs("Processed/%s" % sys.argv[1])
os.system("gunzip -c TAQ/taq_%s_trades_all.csv.gz > %s" % (sys.argv[1], sys.argv[1]))
ifile = open(sys.argv[1])
line = Line(ifile)
stock = Stock(line.symbol)
second = Second(line)
while line.next():
if line.symbol != stock.symbol:
second.next(stock, line)
stock.next(line.symbol)
elif line.time == second.time:
second.add(line)
else:
second.next(stock, line)
second.write(stock)
stock.close()
ifile.close()
os.remove(sys.argv[1])The following R code was used to run the Python script on each date of interest. It processes the files in parallel, making use of all twelve cores on my machine.
require(foreach)
require(doMC)
registerDoMC()
taqdir <- "TAQ"
taqfiles <- list.files(taqdir)
taqfiles <- taqfiles[grep("20.*_trades", taqfiles)]
taqdates <- substring(taqfiles, 5, 12)
taqdates <- c(taqdates[taqdates >= "20100517" & taqdates <= "20100610"],
taqdates[taqdates >= "20110804" & taqdates <= "20111013"])
a <- foreach(taqdate = taqdates, .combine = c) %dopar% {
command <- paste("python TAQprocess.py", taqdate)
system(command)
}Now we have one folder for each date of interest. Within that folder, there is a file for each stock that was represented on that day’s TAQ file. This stock’s file has a row for each second of the day during which trades occurred. Each row consists of two columns: time of day (in seconds) and weighted average trade price during that second. For example,
time,price
34201,52.41
34205,52.4
34210,52.41
34222,52.4
Market Capitalization Data
Next, I made a list of all of the stocks that are represented on every date of interest and stored it as a file called goodstocks.txt.
setwd("Processed")
dates <- list.files()
goodstocks <- list.files(dates[1])
for (date in dates[2:length(dates)]) {
goodstocks <- intersect(goodstocks, list.files(date))
}
goodstocks <- substr(goodstocks, 1, nchar(goodstocks) - 4)
writeLines(goodstocks, "goodstocks.txt", row.names = F)For this list of stocks, I ran a script to scrape the web and determine the number of shares outstanding for each stock during the dates of interest. Note that the outstanding and append.csv functions are detailed in a previous post.
library(XML)
symbols <- readLines("goodstocks.txt")
dates <- c("20100517", "20100610", "20110804", "20111013")
append.csv(dates, "outstanding.csv")
results <- matrix(NA, length(symbols), length(dates))
colnames(results) <- dates
rownames(results) <- symbols
dates <- strptime(dates, "%Y%m%d")
for (i in 1:length(symbols)) {
results[i, ] <- outstanding(symbols[i], dates)
append.csv(results[i, ], "outstanding.csv", rowname = symbols[i])
Sys.sleep(5)
}This creates a file outstanding.csv with the number of shares outstanding on each date for each stock. The first few lines of the file are shown below.
,20100517,20100610,20110804,20111013
A,347930000,347930000,347930000,347930000
AA,1.07e+09,1.07e+09,1.07e+09,1.07e+09
AACC,30770000,30770000,30770000,30770000
AAON,24520000,24520000,24520000,24520000
For many stocks, I was unable to retrieve Yahoo! Finance or GetSplitHistory data, so they were thrown out. Also, any stocks that had a split during either of the periods of interest were discarded from my list of good stocks.
a <- read.csv("outstanding.csv", row.names = 1)
# Discard missing stocks
a <- a[!is.na(a[, 1]), ]
# Discard any stocks that split during either period
a <- a[-which(a[, 1] != a[, 2] | a[, 3] != a[, 4]), ]
write.csv(a, "outstanding.csv")
writeLines(rownames(a), "goodstocks.txt")Finally, multiplying the number of shares outstanding by the share price tells us the market capitalization of each stock for each period. Of course, each stock does not have a single price for each period. Instead, I compute the average price.
require(foreach)
require(doMC)
registerDoMC()
DayAverage <- function(stock, date) {
filename <- paste0(date, "/", stock, ".csv")
x <- read.csv(filename)
n <- length(x$time)
if (n == 1)
return(x$price[1])
total <- 0
for (i in 1:(n - 1)) {
total <- total + x$price[i] * (x$time[i + 1] - x$time[i])
}
total <- total + x$price[n] * (57600 - x$time[n])
avg <- total/(57600 - x$time[1])
return(avg)
}
# Detemine Average Price for each Stock in each Period
stocks <- readLines("goodstocks.txt")
n <- length(stocks)
setwd("Processed")
dates <- list.files()
years <- c("2010", "2011")
prices <- matrix(NA, n, length(years), dimnames = list(stocks, years))
for (i in 1:length(years)) {
yeardates <- dates[grep(years[i], dates)]
m <- length(yeardates)
prices[, i] <- foreach(stock = stocks, .combine = c) %dopar% {
print(paste(years[i], stock))
avgs <- rep(NA, m)
for (j in 1:m) {
avgs[j] <- DayAverage(stock, yeardates[j])
}
return(mean(avgs))
}
}
# Multiply Price by Shares Outstanding to get Market Cap
setwd("..")
shares <- read.csv("outstanding.csv", row.names = 1)
cap <- cbind(shares[, 1] * prices[, 1], shares[, 3] * prices[, 2])
colnames(cap) <- years
write.csv(cap, "cap.csv")Here is a glance at the spread of market caps.
boxplot(log(cap), main = "Market Capitalizations", ylab = "Natural Log of Dollars")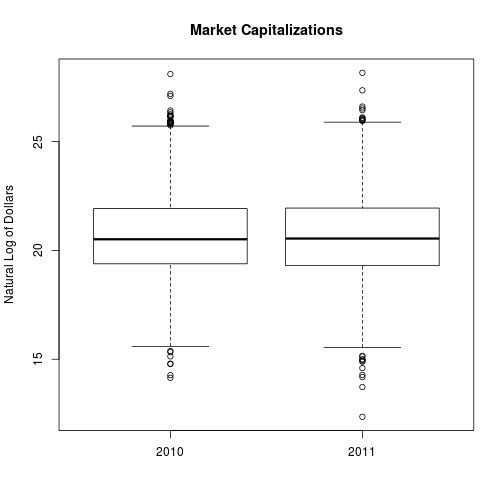
Cleaning the Data
On some holidays the stock market is only open for a shortened trading day. If any partial trading days are present in my data set I should throw them out. I would guess that any partial trading days should have noticably less trading activity than ordinary trading days. I made a boxplot of trading activity to look for lower outliers, but there were none. As a result, I assume there are no partial trading days in my data set.
stocks <- readLines("goodstocks.txt")
n <- length(stocks)
setwd("Processed")
dates <- list.files()
activity <- matrix(NA, n, length(dates), dimnames = list(stocks, dates))
for (i in 1:length(dates)) {
files <- paste0(dates[i], "/", stocks, ".csv")
for (j in 1:n) {
command <- paste("wc -l", files[j])
r <- system(command, intern = T)
activity[j, i] <- as.integer(unlist(strsplit(r, " "))[1]) - 1
}
}
write.csv(activity, "activity.csv")
means <- apply(activity, 2, mean)
boxplot(log(means), main = "Trading Activity Each Day",
ylab = "Log of Avg Number of Seconds in which Trades Occurred")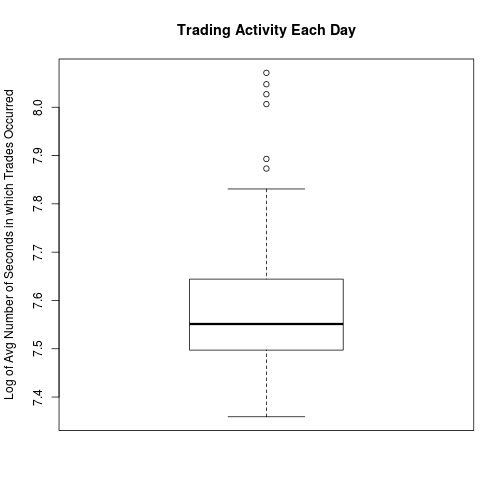
Ultimately, we want to compare SSCB stocks to non-SSCB stocks, in hopes of determining differences caused by the SSCB rules. To that end, we should try to control for trading activity. In other words, we want amount of trading activity to be about the same within the two groups. The SSCB stocks are, on average, more frequently traded. Therefore, I expect to toss out many of the obscure and infrequently traded non-SSCB stocks in order to make the two groups more similar.
SSCBstocks <- readLines("RussellOrSP.txt")
mins <- apply(activity, 1, min)
sscb <- names(mins) %in% SSCBstocks
boxplot(log(mins) ~ sscb, main = "Trading Activity Each Stock",
ylab = "Log of Min Number of Seconds in which Trades Occurred",
names = c("non-SSCB", "SSCB"))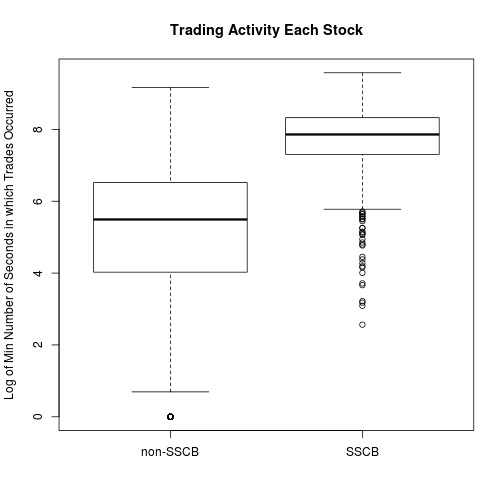
I decided to discard any stock that had a day of fewer than 400 seconds of trading. The non-SSCB group still skews lower, but at least they are in the same ballpark now.
mins <- mins[mins >= 400]
sscb <- names(mins) %in% SSCBstocks
boxplot(log(mins) ~ sscb, main = "Trading Activity Each Stock",
ylab = "Log of Min Number of Seconds in which Trades Occurred",
names = c("non-SSCB", "SSCB"))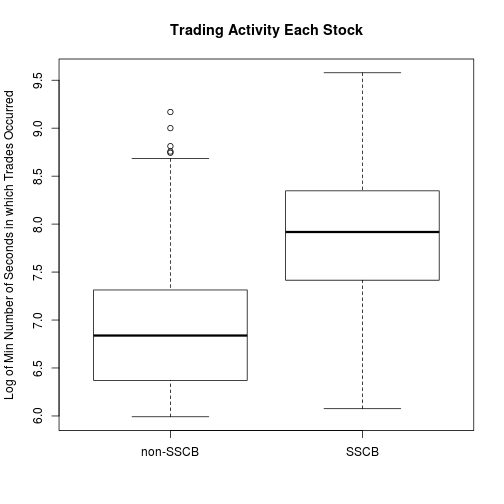
How many stocks are left for the analysis?
writeLines(names(mins), "goodstocks.txt")
print(paste(length(mins), "stocks remaining."))
## [1] "1690 stocks remaining."
print(paste(sum(sscb), "SSCB stocks."))
## [1] "694 SSCB stocks."
print(paste(sum(!sscb), "non-SSCB stocks."))
## [1] "996 non-SSCB stocks."Estimating Volatility Profiles
Now that the stock data has been simplified, cleaned, and organized into manageable chunks, we can estimate volatility profiles as described in a prior post.
require(foreach)
require(doMC)
registerDoMC()
Prices <- function(S, times) {
m <- length(S$price)
n <- length(times)
p <- rep(NA, n)
j <- 1
for (i in 1:n) {
while (j < m) {
if (S$time[j + 1] > times[i])
break
j <- j + 1
}
p[i] <- S$price[j]
}
return(p)
}
out.discard <- function(x, threshold = 3) {
scores <- (x - mean(x)) / sd(x)
return(x[abs(scores) <= threshold])
}
X <- function(S, l = 5) {
x <- out.discard(x)
times <- seq(34200, 57600, by = 60 * l)
p <- Prices(S, times)
return(p[-1]/p[-length(times)])
}
Y <- function(x, l = 5) {
num <- sum((x - mean(x))^2)
denom <- (length(x) - 1) * l/60/6.5/252
return(num/denom)
}
Profile <- function(stock, dates, period, l = 5) {
if (390%%l)
stop("Error: Interval length should divide 390.")
stockfiles <- paste0("Processed/", dates, "/", stock, ".csv")
print(paste("Profiling", stock))
M <- matrix(NA, length(dates), 390/l)
for (i in 1:length(dates)) {
S <- read.csv(stockfiles[i])
M[i, ] <- X(S, l)
}
filename <- paste0("Profiles/", period, "/", stock, ".csv")
print(paste("Creating", filename))
write.csv(M, filename)
result <- rep(NA, 390/l)
try(result <- apply(M, 2, Y), silent = T)
return(result)
}
stocks <- readLines("goodstocks.txt")
dates <- list.files("Processed")
for (year in c("2010", "2011")) {
yeardates <- dates[grep(year, dates)]
a <- matrix(unlist(mclapply(stocks, Profile, yeardates, year)),
nrow = length(stocks), byrow = T)
rownames(a) <- stocks
write.csv(a, paste0(year, ".csv"))
}Here’s a typical example of a squared volatility profile.
vols <- read.csv("2010.csv", row.names = 1)
t <- 2.5 + 5 * (0:77)
set.seed(2)
i <- runif(1, 1, nrow(vols))
plot(t, vols[i, ], main = rownames(vols)[i], xlab = "Minutes into Day",
ylab = "Squared Volatility")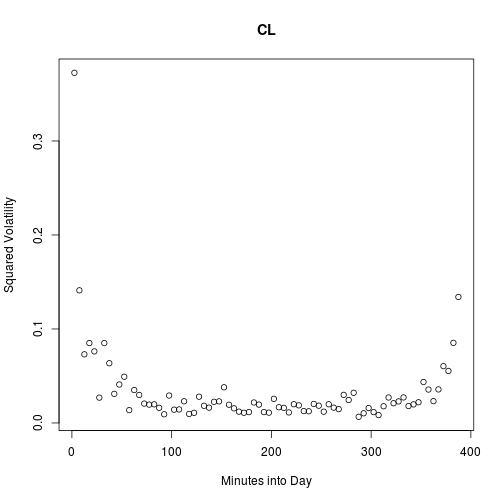
blog comments powered by Disqus